
Scrapy, a renowned web scraping framework, offers efficiency and flexibility. When combined with Playwright, a modern browser automation library, your scraping endeavors are taken to new heights. In this step-by-step tutorial, we'll walk you through the process of harnessing the power of Scrapy-Playwright to effortlessly extract accurate data from websites.
Prerequisites:
- Basic understanding of Python and scrapy.
- Familiarity with web scraping concepts.
- Python and pip installed on your machine.
1. step 1: Setting up the playground:
In this example we will scrape a sandbox website called quotes.toscrape.com where it has a js constructed quotes page with few seconds delay before the page is constructed. And for that, scrapy playwright intergration is somehow necessary.
let's install the requirements:
pip install scrapy
pip install scrapy-playwright
Now that playwright is installed, it needs the browsers installed. For that we enter the following command:
playwright install
After that, let's create a scrapy project named quotesjs and enter it:
scrapy startproject quotesjs
cd quotesjs
And last touch, we introduce playwright to scrapy by adding download handlers. For that, we add the two download handlers to quotesjs/settings.py :
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
2. Spider setting and scraping:
Now that scrapy can work with playwright, We create a new spider named quote that would scrape quotes from our target website:
scrapy genspider quote "http://quotes.toscrape.com/"
we open the spider import PageMethod, set target url and the start_requests to the following:
import scrapy
from scrapy_playwright.page import PageMethod
class QuoteSpider(scrapy.Spider):
name = "quote"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["http://quotes.toscrape.com/js-delayed"]
def start_requests(self):
yield scrapy.Request(
url=self.start_urls[0],
meta={
"playwright": True,
"playwright_page_methods": [
PageMethod("wait_for_selector",
'[class="quote"]')
]}
)
In the code above, we specified for scrapy that this request is going to use playwright, and it will wait for a specific item to be presente in the page before parsing he response, This way we assure the presence of the items to scrape, and we avoid errors and wasting time by using time.sleep.
Now, all what's left is to scrape the quotes in the parse method:
def parse(self, response):
items = response.xpath("//div[@id='quotesPlaceholder']/div")
for item in items:
yield {
'content': item.xpath(".//span[@class='text']/text()").get(),
'author': item.xpath(".//small[@class='author']/text()").get(),
'tags': item.xpath(".//div[@class='tags']/a/text()").getall()
}
To see the browser in action we will need to add some options to playwright in settings.py as follows:
PLAYWRIGHT_LAUNCH_OPTIONS = {
"headless": False,
}
now let's launch the crawl and see what happens.
scrapy crawl quote
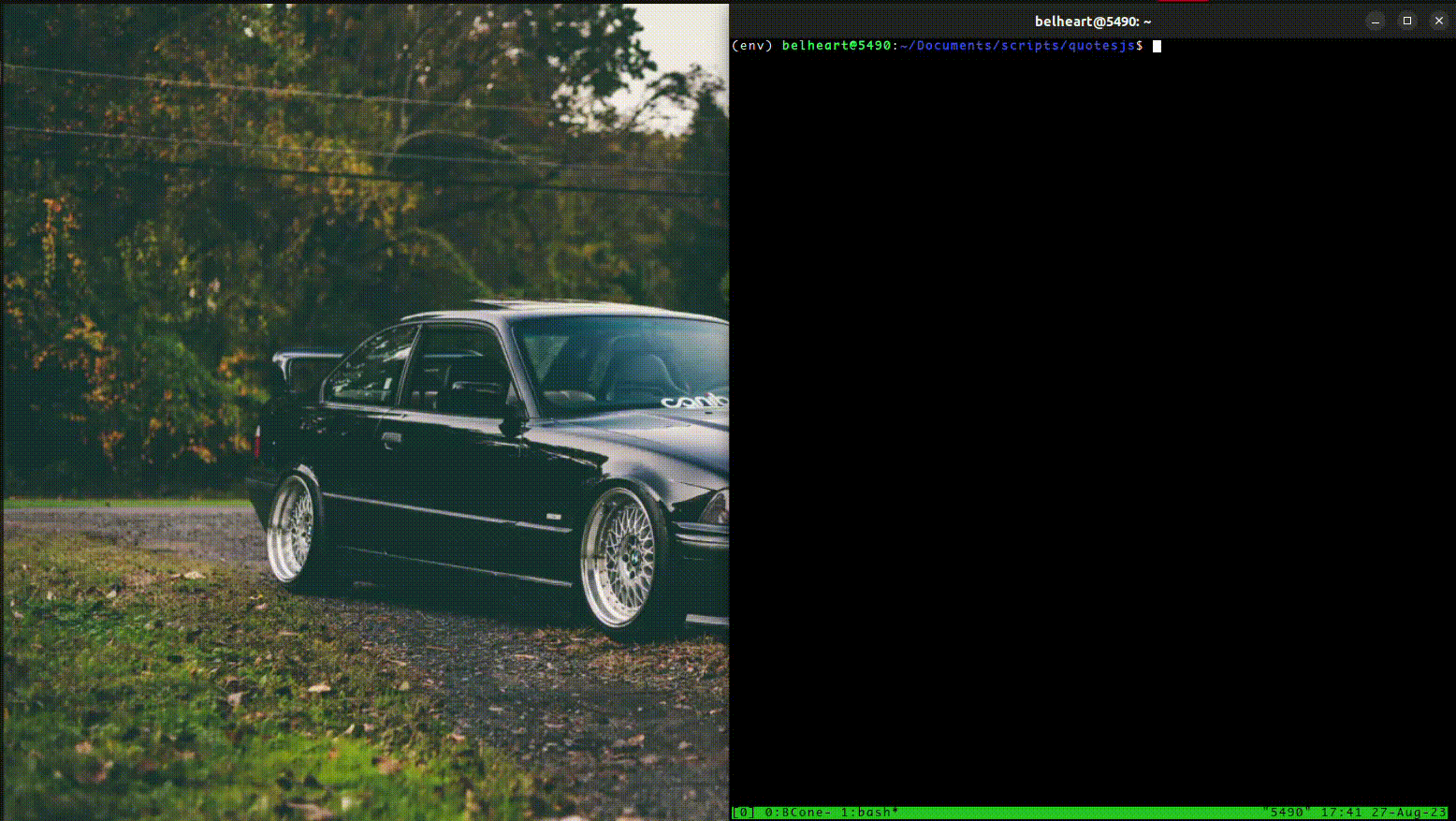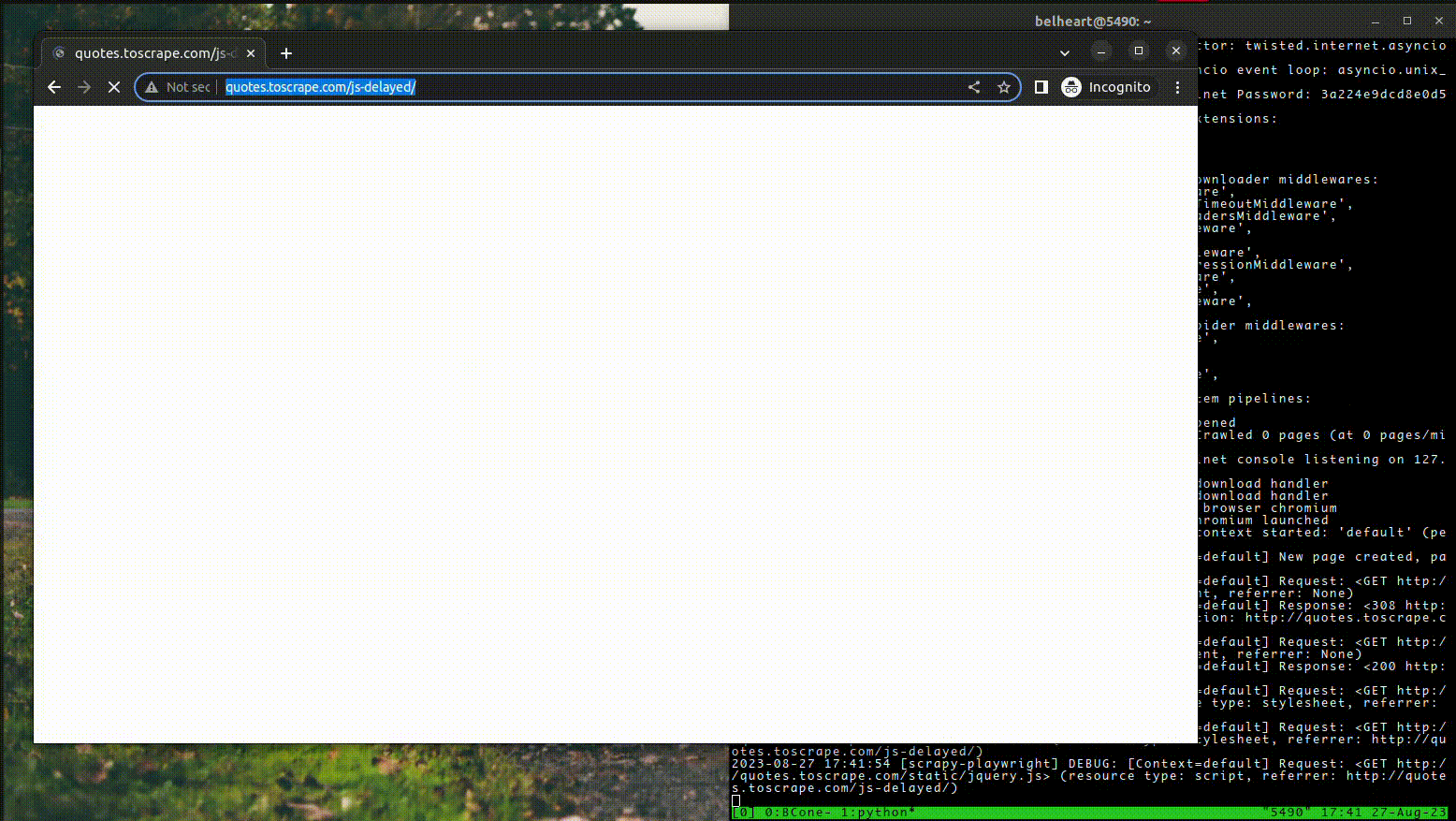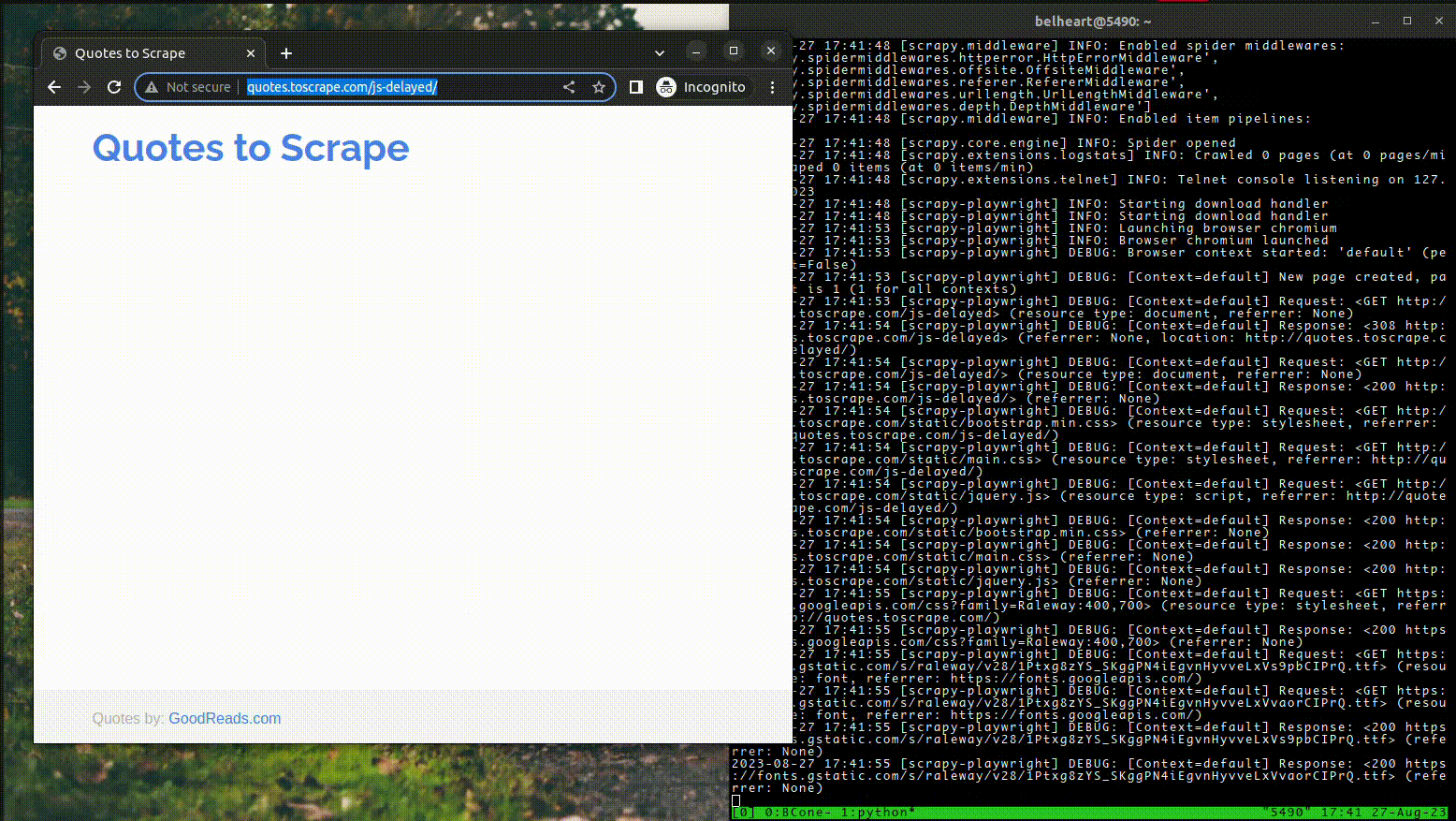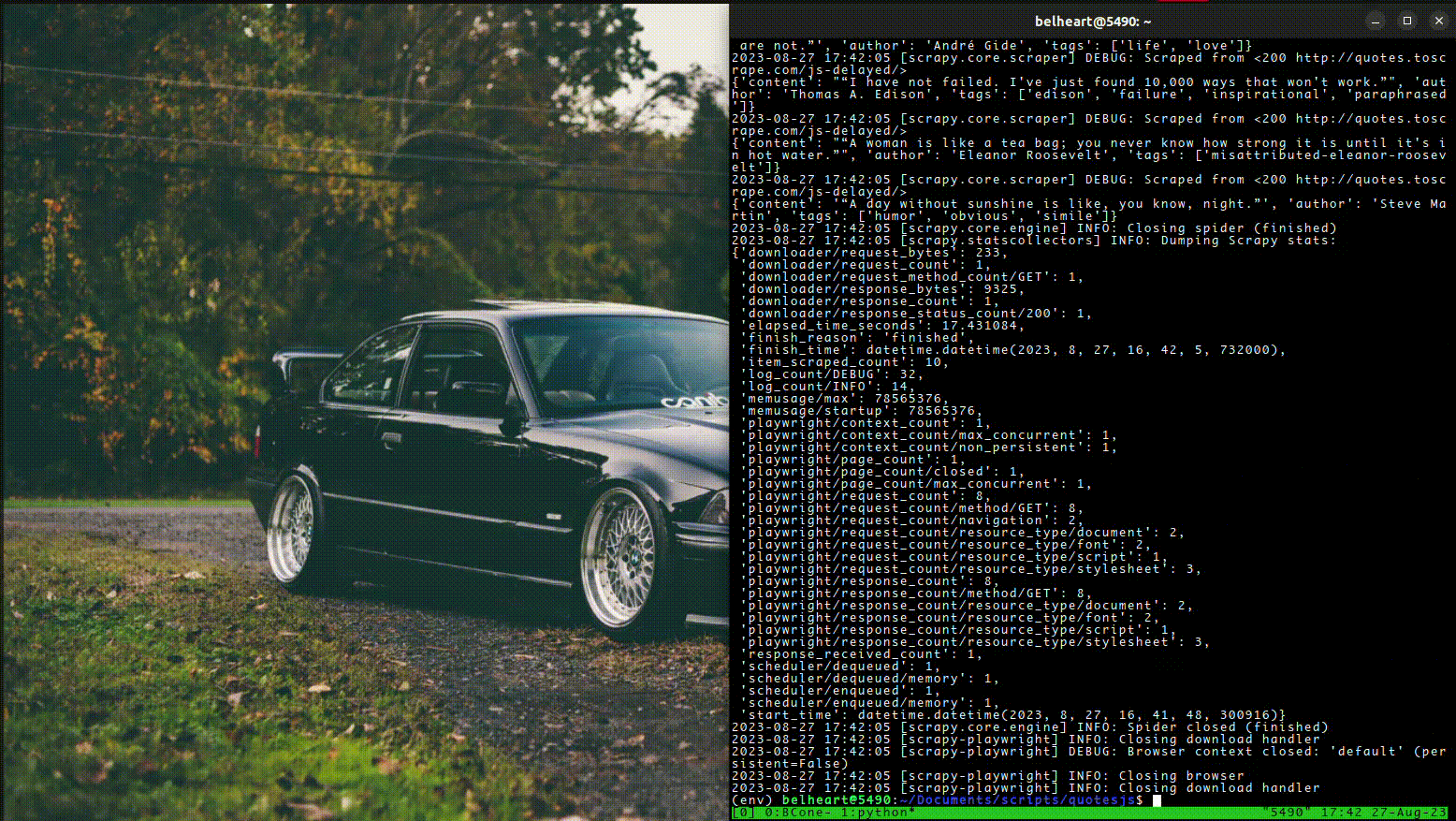
3. Conclusion:
After we laumched the scraper, the browser started and loaded the start url fully. And then, it waited for the presence of quotes in page and only then the parsing started.
This method is favorable programatically, because it ensure you the presence of items even after the page fully loaded and avoid unecessary waiting time using the usual sleep method.