
While Scrapy excels in the art of data extraction, the need for comprehensive data storage and management has given rise to the strategic integration of SQLAlchemy. This guide is designed to provide you with a detailed exploration of this powerful amalgamation. So let's learn by doing, I have a ready scrapy project that we will implement SQLAlchemy ORM to it.
For this you're going to need the following packages:
- pymysql
- sqlalchemy
This tutorial assumes that you already have knowledge in scrapy and pipelines, and that's why i have a scrapy project ready that scrapes zalora website and yield product item scraped from the website, check below:
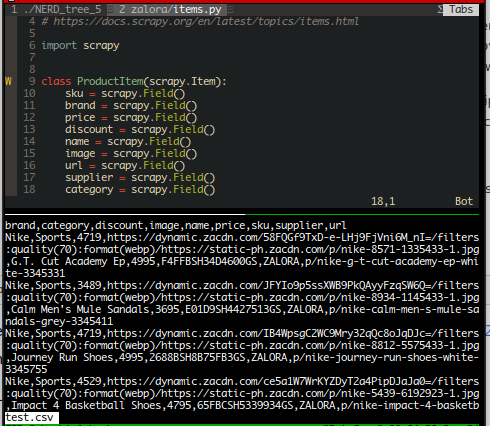
What we will do is to pipeline those products into a mysql table through scrapy's pipeline.
So first thing is to make the model which will connect to the database, create the table if not found and match the item and copy data from it, create a file named model.py and write in the following:
from sqlalchemy import create_engine, Column, Table, ForeignKey, MetaData
from sqlalchemy.orm import relationship, declarative_base
from sqlalchemy import (
Integer, String, Date, Date, Float, Boolean, Text)
from scrapy.utils.project import get_project_settings
Base = declarative_base()
def db_connect():
"""
connects to database using credentials from settings.py
returns SQLAlchemy engine
"""
return create_engine(get_project_settings().get("CONNECTION_STRING"))
def create_table(engine):
Base.metadata.create_all(bind=engine)
class product(Base):
__tablename__ = "zalora_products"
id = Column(Integer, primary_key=True)
sku = Column(String(16))
brand = Column(String(50))
price = Column(Integer)
discount = Column(Integer)
name = Column(String(250))
image = Column(String(300))
url = Column(String(250))
supplier = Column(String(50))
category = Column(String(50))
The connection string is a string with the following format that will allow you to connect to the database:
mysql+pymysql://[username]:[password]@[host]/[database]
every model(Base class) should have a table name and a primary key as the example above.
Now, with the model ready we need to prepare the pipeline to do the magic and pass in the item:
from sqlalchemy.orm import sessionmaker
from zalora.items import ProductItem
from zalora.model import (
product,
db_connect,
create_table
)
class ZaloraPipeline:
def __init__(self):
# WE FIRST GET THE CONNECTION FROM THE MODEL AND START A SESSION
engine = db_connect()
create_table(engine)
self.Session = sessionmaker(bind=engine)
def process_item(self, item, spider):
# PASS THE SESSION FOR PROCESSING
session = self.Session()
# IN CASE OF HAVING MULTIPLE ITEMS, YOU SHOULD CHECK THE INSTANCE OF IT
# IN ORDER TO MATCH IT WITH THE CORRESPONDING MODEL
if isinstance(item, ProductItem):
# PASS IN ALL ITEM FIELDS INTO THE MODEL COLUMNS.
prod = product(**item)
# CHECK IF THE ITEM EXISTS IN THE TABLE
exist_prod = session.query(product).filter(
product.sku == item['sku']).first()
# IF EXISTS, THEN UPDATE THE FIELDS THAT CHANGED
if exist_prod:
exist_prod.price = item['price']
exist_prod.discount = item['discount']
# IF NOT, THEN ADD IT AS NEW ROW
else:
session.add(prod)
# COMMMIT AND CLOSE THE CONNECTION
session.commit()
session.close()
# RETURN THE ITEM
return item
Please check the commented lines in order to better understand the approach used.
One last thing, all what we need to do is to add the connection string and the pipeline into the settings.py, by adding the following lines:
CONNECTION_STRING = "mysql+pymysql://[username]:[password]@[host]/[database]"
ITEM_PIPELINES = {
"zalora.pipelines.ZaloraPipeline": 300,
}
Finally we launch the crawling and check for the results:
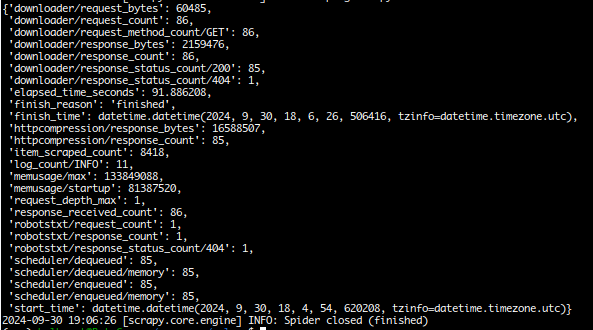
You will notice that the scrape take a little longer than without the pipeline and that depends on the DB connection if it is local or remote.
By checking the database table, you will find all the data available, with possible duplicates removed since we check each time for product existance by filtering SKU.
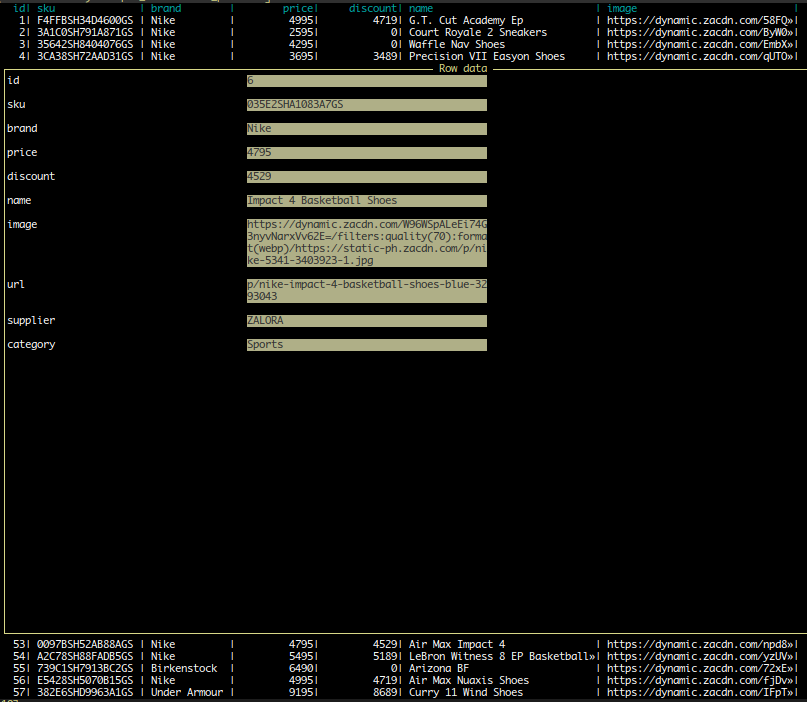
In conclusion, sqlalchemy is a great tool to make a clean and robust database connection with avoiding all the long sql queries.
and I order to minimise the long connection time and session creation, what you can do is to bulk dump items into database, this way you create less sessions at a time.