
Most of the times you will face a website where you have to go through multiples numbered pages to get all data or search results. And unfortunately, the majority do it the wrong way and end up wasting valuable scraping time in the process.
In this post, we are going through what you might be doing wrong, why is it wrong and show you the proper way of doing it. So launch your editor and let's head straight into it.
The problem
In web scraping you will want to make the scraping goes as fast as possible especially with large data and big websites, and being a professional that uses scrapy you will be using scrapy's async core to do the scraping which is very fast ONLY if used correctly.
most beginners will go for a linear scraping which means they will go for page-1 scrape it and from there request page-2 and scrape it and so on, and that is counter productive. let's take a look at two examples one where we go for linear requests and the other where we yield all the requests into async core.
Example 1 (linear)
import scrapy
class LinearSpider(scrapy.Spider):
name = "linear"
allowed_domains = ["books.toscrape.com"]
start_urls = ["http://books.toscrape.com/catalogue/page-1.html"]
def parse(self, response):
books = response.xpath("//article[@class='product_pod']")
for book in books:
yield {
'title': book.xpath(".//h3/a/@title").get(),
'image': book.xpath(".//img/@src").get(),
'price': book.xpath(".//p[@class='price_color']/text()").get(),
}
_next = response.xpath("//a[text()='next']/@href").get()
if _next:
yield scrapy.Request(
url="http://books.toscrape.com/catalogue/"+_next,
callback=self.parse
)
From the the code above web kept checking if a next page exists after we scrape each page and request it to so on one after another, The result and time spent was as below :
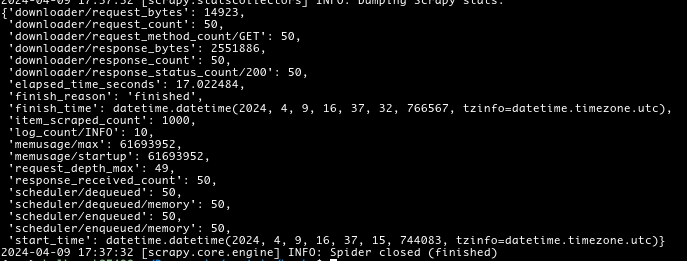
It took the spider 17 seconds to go through all 50 pages and scrape them, which is very slow when scraping a big website. Let's see the correct way of doing things
Example 2 (yield requests)
import scrapy
class LinearSpider(scrapy.Spider):
name = "linear"
allowed_domains = ["books.toscrape.com"]
def start_requests(self):
totalPages = int(1000/20)
for i in range(1, totalPages+1):
yield scrapy.Request(
url=f"http://books.toscrape.com/catalogue/page-{i}.html"
)
def parse(self, response):
books = response.xpath("//article[@class='product_pod']")
for book in books:
yield {
'title': book.xpath(".//h3/a/@title").get(),
'image': book.xpath(".//img/@src").get(),
'price': book.xpath(".//p[@class='price_color']/text()").get(),
}
In the above code we calculated how many pages we have since there are 1000 books and 20 books per page makes 50 pages, after that we went in a loop yielding all pages by number and dumping them into the core, finally the results were way better than the previous result:
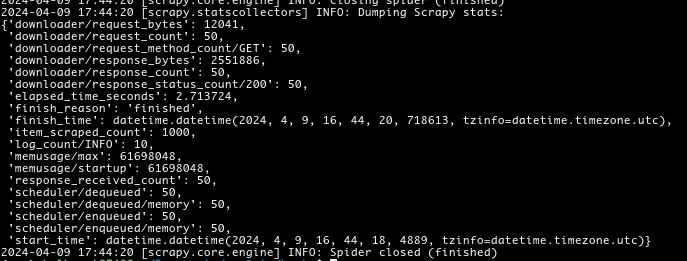
It took the spider only 2.7 seconds to go through all 50 pages scraping all 1000 books. Which makes yielding the request way faster and more efficient.
Conclusion
Making the mistake of linear scraping when using scrapy can cost you too much lost time and resources, Especially if it is a large scale scraping.
async programming is much advised but the most important thing is to determine in advance how many pages you have, for demonstration purposes the pages counts was hardcoded in the above example but the better way is to scrape and calculate it dynamically, this way you won't miss new pages if added to website and don't have to update it each time there is.